Ghost scrubbing with a Python


So remember that fancy Static Generated version of my Ghost CMS blog I was bragging about? I may have gotten too excited and overlooked something.
Overlooked something kind of important, namely mobile experience.
Ok so maybe it wasn't working so smooth. Let's see what's going on this time.
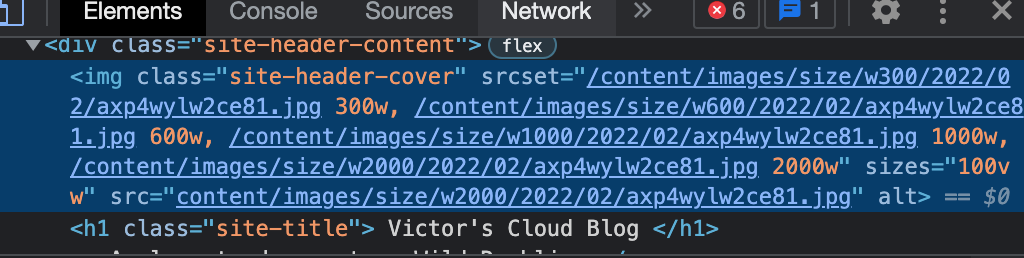
Chrome's native Inspect tool is rad. Looking through the image elements in that header, it shows me which images exist and which ones don't. The filenames and directories look fine, so not the same problem as wget, but for some reason some of the elements don't appear in the quick inspect tool, particularly the 600w and the 1000w sizes.
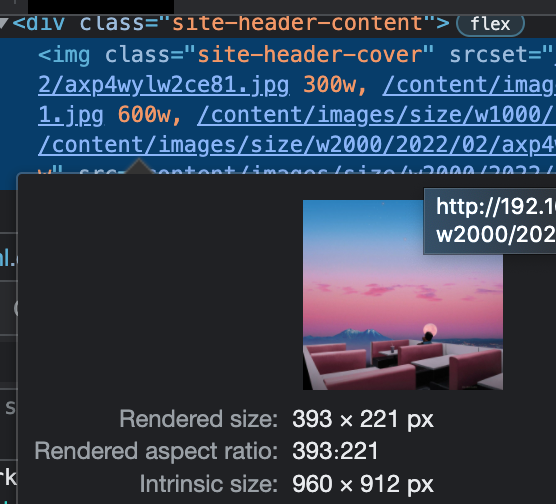
Let's dig a bit into the file system and take a looksy.
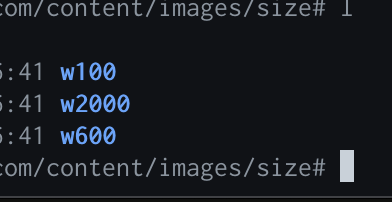
Interesting, so I'm not seeing the w1000 or w300 subfolder for the mobile optimized images that Ghost produces. And the ones that do exist look like they aren't producing all of the size-optimized imagery it should for each page.
Ok, so maybe httrack isn't flawless, but should be pretty easy to set an option to produce a mobile-view request and re-run httrack to give me an overlay of a mobile site version and merge the two, right?
Right?
Httrack is kind of old
Like myself, httrack pre-dates mobile-centric technology, and though it's creator still appears to be on the web and active, the git page shows last update some years ago, and in a 1 year old forum post the Author says he's not actively maintaining it, so mobile-centric views are unlikely to be integrated.
So when it comes to server-side javascript hosts, there is something about srcsets and javascript or some gobbledegook that prevents them from being called in. Yuck.
Ok, maybe we can throw something together with the original source clone, a little C won't hurt
Have I mentioned I can be incredibly lazy? I don't want to do all of that, I just want something fast and easy and cheap!
Ok so httrack doesn't have any options for changing viewport sizes, what about adding to the sitemap.xml telling httrack to crawl the non-apparent subfolders and images? That should be able to direct well enough right?
Aaaand changing sitemap output from Ghost requires digging in the JS source. Cmon! I'm trying to be lazy here!
Ok stepping back a second, wget was able to produce a mostly working site, which just needed a little scrubbing to fix some weird filename errors. But at least it generated the full list of available image sources.
If I'm going to code, I want to do as little as possible. Let's revisit and see what is going on here.
Ever clean something with a Python, Jimmy?
It looks like this wget issue seems to vex Ghost sites, and while I see a script here that can scrub the output files using some find/sed commands, I've been learning more about python and would like to use that since it's kind of housed all in one bundle instead of a series of different apps (granted they are native apps, and typically found on every install). I just want an excuse to use Python ok?
So back to the original problem, if some code is involved, let's keep it minimal!
Since I don't want to reinvent the wheel I looked for a quick find-and-replace script that would fit the bill, of which there were many. The one that I thought was simple and elegant enough was using the os.walk method and fnmatch to recognize file types, making it easier for me to wrap my puny mortal brain around.
import os, fnmatch
def findReplace(directory, find, replace, filePattern):
for path, dirs, files in os.walk(os.path.abspath(directory)):
for filename in fnmatch.filter(files, filePattern):
filepath = os.path.join(path, filename)
with open(filepath) as f:
s = f.read()
s = s.replace(find, replace)
with open(filepath, "w") as f:
f.write(s)
findReplace(".", "jpg", "jpg", "*.html")
findReplace(".", "jpg", "jpg", "*.html")
findReplace(".", "jpg", "jpg", "*.html")
This script should jog though primary folder and subfolders looking for html files, inspect them for mangled jpg extensions, and then scrub-a-dub-dub.
So back to our ol' pal wget, run mirror, then run python script and BEHOLD, IT'S ALIVE!
Ok time to be excited again!
Checking the internal htmls I can see that the jpg extensions have been scrubbed correctly across the board, and should I encounter any future issues with mangling I can just add+adjust the python easily and quickly.
So at this point I edit my GitHub Actions dev directive file to remove the previous httrack code, and in order to integrate the python I just need to tag in a new extension for jannekem/[email protected] which let's me run the code inside the Action YML, making sure I set up a python env prior to calling it
steps:
- name: Checkout
uses: actions/[email protected]
- name: Setup python support
uses: actions/[email protected]
with:
python-version: ${{ matrix.python-version }}
- name: Mirror ghosty site
run: wget -E -r -k -p -q https://mysite
- name: run Python stuff
uses: jannekem/[email protected]
with:
script: |
import os, fnmatch
def findReplace(directory, find, replace, filePattern):
for path, dirs, files in os.walk(os.path.abspath(directory)):
for filename in fnmatch.filter(files, filePattern):
filepath = os.path.join(path, filename)
with open(filepath) as f:
s = f.read()
s = s.replace(find, replace)
with open(filepath, "w") as f:
f.write(s)
findReplace(".", "jpg", "jpg", "*.html")
findReplace(".", "jpg", "jpg", "*.html")
findReplace(".", "jpg", "jpg", "*.html")
print("Ghost Scrubber Executed")
And after massaging the YML for spacing and ... more spacing.. and syntax.. and more spacing... that's what came out with no errors, and runs to completion.
Anddddd VOILA! (again, but for reals this time)
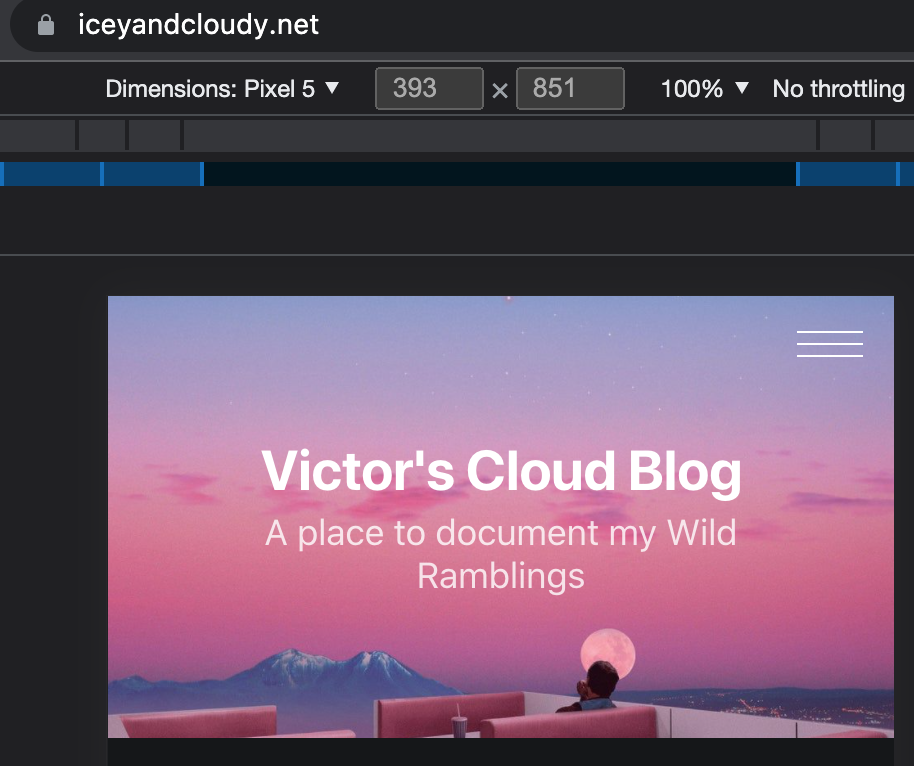
The site is fully functional on the CF+S3 bucket with mobile views enabled, and nary a problem to be seen!
(ok now what is the deal with the cloudflare and email link? I'll explore that later)
Yup! Everything is happy in happy land!
On to the next project, invoking an Action everytime I make a change to the site's content, that way I just focus just on publishing posts and the machines handle the rest.